
Compute Express Link(CXL) 3.0 출시, CPU 상호 연결 전쟁에서 승리

| 출처 | https://www.tomshardware.com/news/cxl-30-debuts-one-cpu-interconnect-to-rule-them-all |
|---|
https://www.tomshardware.com/news/cxl-30-debuts-one-cpu-interconnect-to-rule-them-all
CXL은 CPU 상호 연결 전쟁의 확실한 승자로 떠오릅니다.

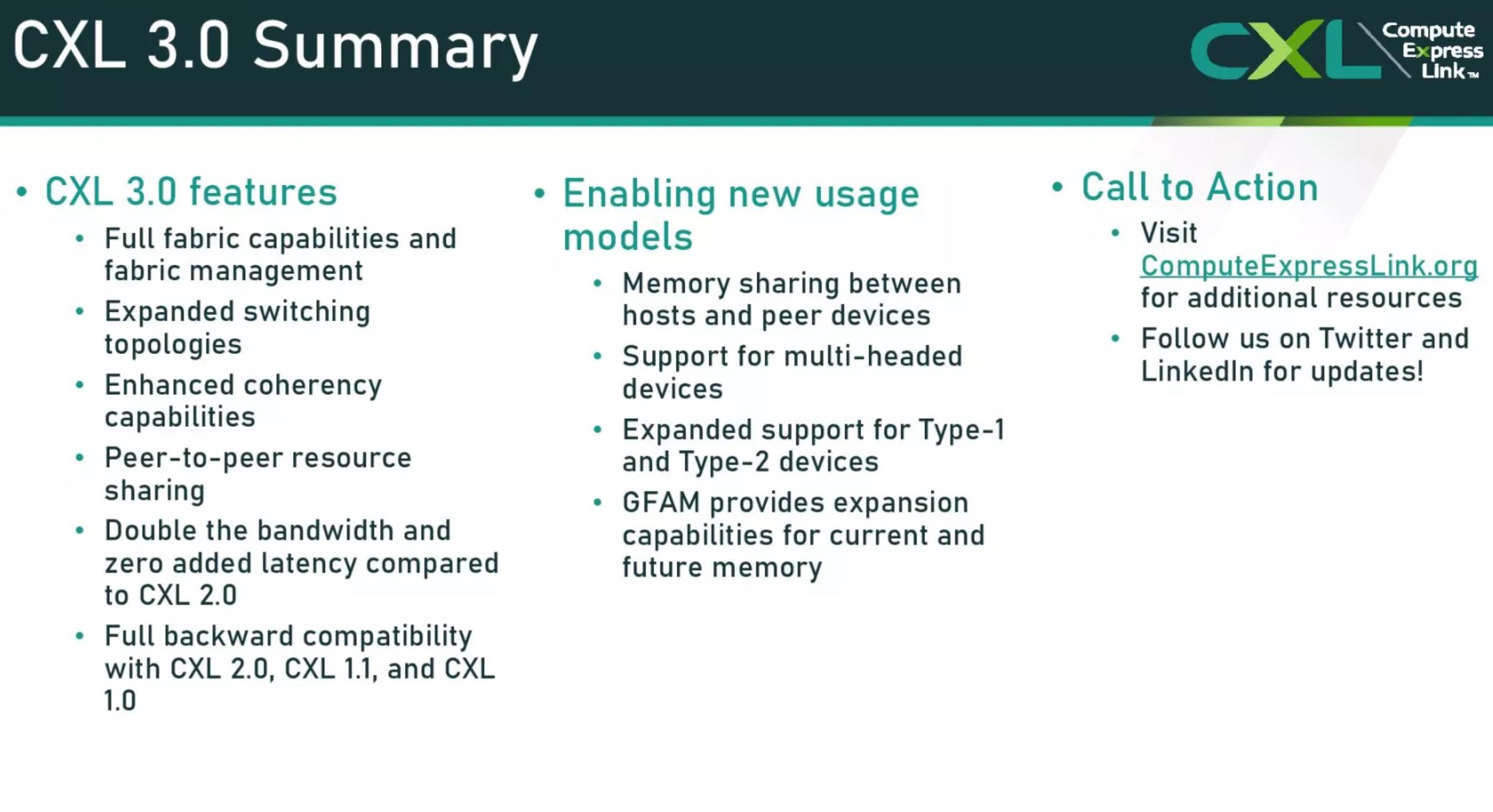
Compute eXpress Link(CXL) 컨소시엄은 오늘 PCIe 6.0 인터페이스 , 메모리 풀링, 더 복잡한 스위칭 및 패브릭 기능 지원과 같은 새로운 기능을 제공하는 CXL 3.0 사양을 공개했습니다 . 전반적으로 새 사양은 이전 버전의 사양과의 역호환성을 유지하면서 대기 시간을 추가하지 않고 최근 개정판의 대역폭을 최대 2배까지 지원합니다. 새로운 사양은 CPU 상호 연결 전쟁에서 마지막으로 의미 있는 공개 경쟁인 OpenCAPI가 어제 CXL 컨소시엄에 사양을 제공할 것이라고 발표하면서 CXL이 업계를 위한 명확한 길로 남게 되었다고 발표하면서 나왔습니다.
참고 로 CXL 사양 은GPU, DPU와 같은 스마트 I/O 장치, 다양한 DDR4/DDR5 및 영구 메모리와 같은 가속기와 CPU 간의 캐시 일관성 상호 연결을 제공하는 개방형 산업 표준입니다. 상호 연결을 통해 CPU는 연결된 장치와 동일한 메모리 영역에서 작업할 수 있으므로 소프트웨어 복잡성과 데이터 이동을 줄이면서 성능과 전력 효율성을 향상시킬 수 있습니다.
모든 주요 칩 제조업체는 AMD의 곧 출시될 Genoa CPU 와 Intel의 Sapphire Rapids 가 1.1 개정판을 지원하면서 사양을 수용했습니다( 후자에 대한 주의 사항 ). Nvidia, Arm 및 수많은 메모리 제조업체, 하이퍼스케일러 및 OEM도 합류했습니다.
새로운 CXL 3.0 사양은 업계가 표준 뒤에 마침내 그리고 완전히 통합됨에 따라 빛을 발하게 되었습니다. 어제 OpenCAPI 컨소시엄은 액셀러레이터에 대한 경쟁 캐시 일관성 OpenCAPI 사양과 직렬 연결 OMI(Open Memory Interface) 사양을 CXL 컨소시엄으로 이전할 것이라고 발표했습니다. 이로써 Gen-Z 컨소시엄 도 올해 초 CXL에 흡수된 후 CXL 표준을 위한 의미 있는 마지막 경쟁이 끝났 습니다 . 또한 CCIX 표준은 여러 파트너가 동요하고 대신 CXL을 배포하기로 선택한 후 없어진 것으로 보입니다.


(이미지 크레디트: toms hardware)
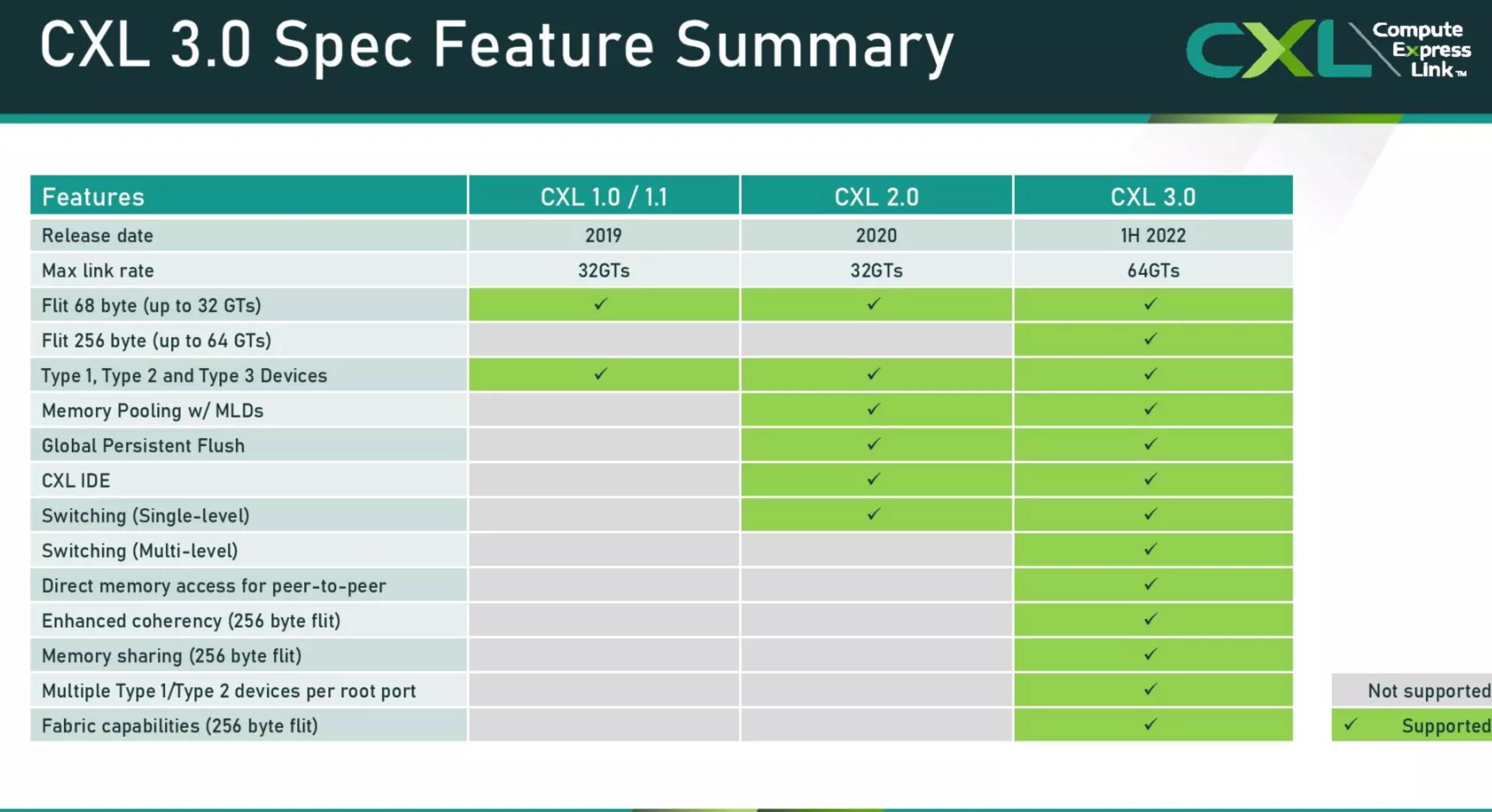
CXL 2.0은 현재 PCIe 5.0 버스를 사용하지만 CXL 3.0은 이를 PCIe 6.0까지 가져와 처리량을 64GT/s(x16 연결의 경우 최대 256GB/s의 처리량)로 두 배로 늘렸지만 대기 시간은 추가되지 않았다고 주장합니다. CXL 3.0은 대기 시간에 최적화된 새로운 256바이트 플릿 형식을 사용하여 대기 시간을 2~5ns 줄여 이전과 동일한 대기 시간을 유지합니다.
다른 주목할만한 개선 사항에는 연결된 장치 간의 네트워킹과 같은 토폴로지, 메모리 공유 및 연결된 가속기 간의 피어 투 피어 통신을 위한 DMA(직접 메모리 액세스)를 가능하게 하는 다중 레벨 스위칭 지원이 포함되어 일부 사용 사례에서 CPU 오버헤드를 제거합니다. .
(이미지 크레디트: CXL 컨소시엄)
이제 CXL 사양을 통해 단일 토폴로지 내에서 여러 스위치를 계단식으로 연결할 수 있으므로 연결된 장치의 수와 패브릭의 복잡성이 Spine/Leaf, 메시 및 링 기반 아키텍처와 같은 비트리 토폴로지를 포함하도록 확장됩니다.
새로운 PBR(Port Based Routing) 기능은 최대 4,096개의 노드를 지원하는 확장 가능한 주소 지정 메커니즘을 제공합니다. 각 노드는 기존 세 가지 유형의 장치 또는 새로운 GFAM(Global Fabric Attached Memory) 장치일 수 있습니다. GFAM 장치는 호스트 간의 메모리 공유를 허용하기 위해 PBR 메커니즘을 사용할 수 있는 메모리 장치입니다. 이 장치는 단일 장치에서 영구 메모리 및 DRAM과 같은 다양한 유형의 메모리 사용을 지원합니다.
새로운 CXL 사양은 상호 연결의 사용 사례를 대폭 확장하여 랙 규모(및 아마도 그 이상)에서 대규모로 분해된 시스템을 포괄합니다. 당연히 이러한 유형의 기능은 예를 들어 올플래시 스토리지 어플라이언스에 연결하는 것과 같이 스토리지 중심적인 목적에 이것이 실현 가능한지에 대한 질문을 던지며 사양이 이들에 대한 관심을 모으기 시작했다고 들었습니다. 용도의 종류도.
컨소시엄은 또한 회원들이 차세대 서버에서 DDR5 비용을 회피하기 위해 DDR4 메모리 풀을 사용하는 데 큰 관심을 보이고 있다고 밝혔습니다. 이러한 방식으로 하이퍼스케일러는 이미 보유하고 있는(그렇지 않으면 폐기할) DDR4 메모리를 사용하여 더 저렴한 DDR4 메모리를 수용할 수 없는 DDR5 서버 칩과 쌍을 이루는 대규모의 유연한 메모리 풀을 생성할 수 있습니다. 이러한 유형의 유연성은 오늘 공개될 CXL 3.0 사양의 많은 장점 중 하나를 강조합니다.











