보도 자료: 오늘 Meta는 차세대 LLM(대형 언어 모델)인 Meta Llama 3를 출시했습니다. 출시일부터 Intel은 Gaudi 가속기, Xeon 프로세서, Core Ultra 프로세서 및 Arc GPU 전반에 걸쳐 첫 번째 Llama 3 8B 및 70B 모델에 대한 AI 제품 포트폴리오를 검증했습니다.

중요한 이유: AI를 모든 곳에 가져오겠다는 사명의 일환으로 인텔은 자사 제품이 역동적인 AI 공간의 최신 혁신에 대비할 수 있도록 소프트웨어 및 AI 생태계에 투자합니다. 데이터 센터에서 AMX(Advanced Matrix Extension) 가속 기능을 갖춘 Gaudi 및 Xeon 프로세서는 고객에게 역동적이고 광범위한 요구 사항을 충족할 수 있는 옵션을 제공합니다.
Intel Core Ultra 프로세서 및 Arc 그래픽 제품은 로컬 연구 및 개발에 사용되는 PyTorch 및 Intel Extension for PyTorch와 모델 개발 및 추론을 위한 OpenVINO 툴킷을 포함한 포괄적인 소프트웨어 프레임워크 및 도구에 대한 지원을 통해 로컬 개발 수단과 수백만 대의 장치에 대한 배포를 모두 제공합니다. .
Intel에서 실행되는 Llama 3 정보: Llama 3 8B 및 70B 모델에 대한 Intel의 초기 테스트 및 성능 결과는 PyTorch, DeepSpeed, Optimum Habana 라이브러리 및 PyTorch용 Intel Extension을 포함한 오픈 소스 소프트웨어를 사용하여 최신 소프트웨어 최적화를 제공합니다.
- Intel Gaudi 2 가속기는 Llama 2 모델(7B, 13B 및 70B 매개변수)에서 성능을 최적화했으며 이제 새로운 Llama 3 모델에 대한 초기 성능 측정 기능을 제공합니다. Gaudi 소프트웨어의 성숙도를 통해 Intel은 새로운 Llama 3 모델을 쉽게 실행하고 추론 및 미세 조정을 위한 결과를 생성했습니다. Llama 3는 최근 발표된 Gaudi 3 가속기 에서도 지원됩니다 .
- Intel Xeon 프로세서는 까다로운 엔드투엔드 AI 워크로드를 처리하며 Intel은 대기 시간을 줄이기 위해 LLM 결과를 최적화하는 데 투자합니다. Performance-cores(코드명 Granite Rapids)가 탑재된 Xeon 6 프로세서는 4세대 Xeon 프로세서에 비해 Llama 3 8B 추론 지연 시간이 2배 향상되었으며 생성된 토큰당 100ms 미만으로 Llama 3 70B와 같은 더 큰 언어 모델을 실행할 수 있는 기능을 보여줍니다.
- Intel Core Ultra 및 Arc Graphics는 Llama 3에 인상적인 성능을 제공합니다. 초기 테스트에서 Core Ultra 프로세서는 이미 일반적인 인간 읽기 속도보다 빠르게 생성됩니다. 또한 Arc A770 GPU에는 XMX(X e Matrix eXtensions) AI 가속기와 16GB 전용 메모리가 있어 LLM 워크로드에 탁월한 성능을 제공합니다.
Xeon 확장 가능 프로세서
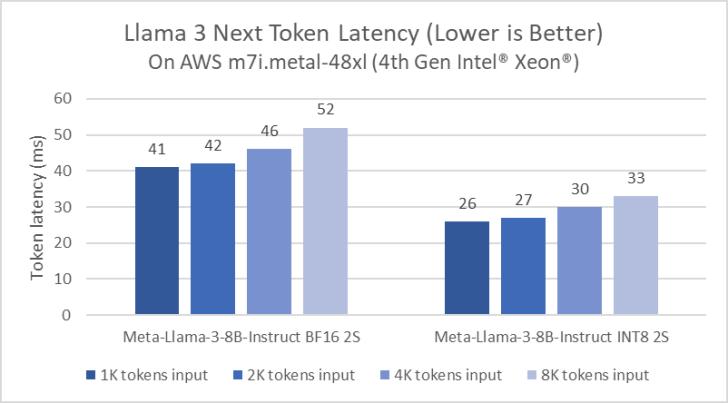
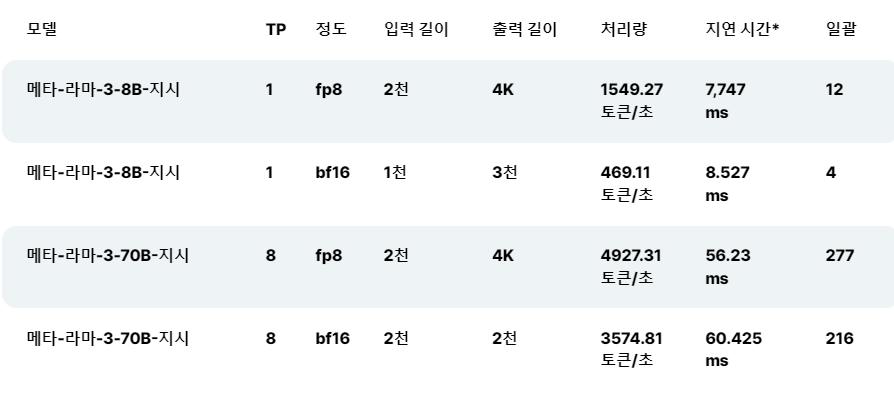
Intel은 Xeon 플랫폼에 대한 LLM 추론을 지속적으로 최적화해 왔습니다. 예를 들어, PyTorch의 Llama 2 출시 소프트웨어 개선과 PyTorch용 Intel Extension은 지연 시간을 5배 단축하는 수준으로 발전했습니다. 최적화에서는 페이징 어텐션과 텐서 병렬을 활용하여 사용 가능한 컴퓨팅 활용도와 메모리 대역폭을 최대화합니다. 그림 1은 4세대 Xeon Scalable 프로세서를 기반으로 하는 AWS m7i.metal-48x 인스턴스에서의 Meta Llama 3 8B 추론 성능을 보여줍니다.
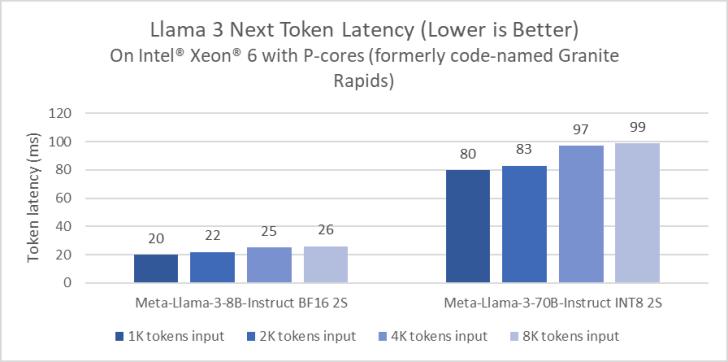
성능 미리보기를 공유하기 위해 Performance 코어(이전의 코드명 Granite Rapids)를 갖춘 Xeon 6 프로세서에서 Meta Llama 3를 벤치마킹했습니다. 이러한 미리 보기 수치는 Xeon 6이 널리 사용되는 4세대 Xeon 프로세서에 비해 Llama 3 8B 추론 지연 시간이 2배 향상되었으며 Llama 3 70B와 같은 더 큰 언어 모델을 단일 2개의 프로세서에서 생성된 토큰당 100ms 미만으로 실행할 수 있음을 보여줍니다. 소켓 서버.
클라이언트 플랫폼
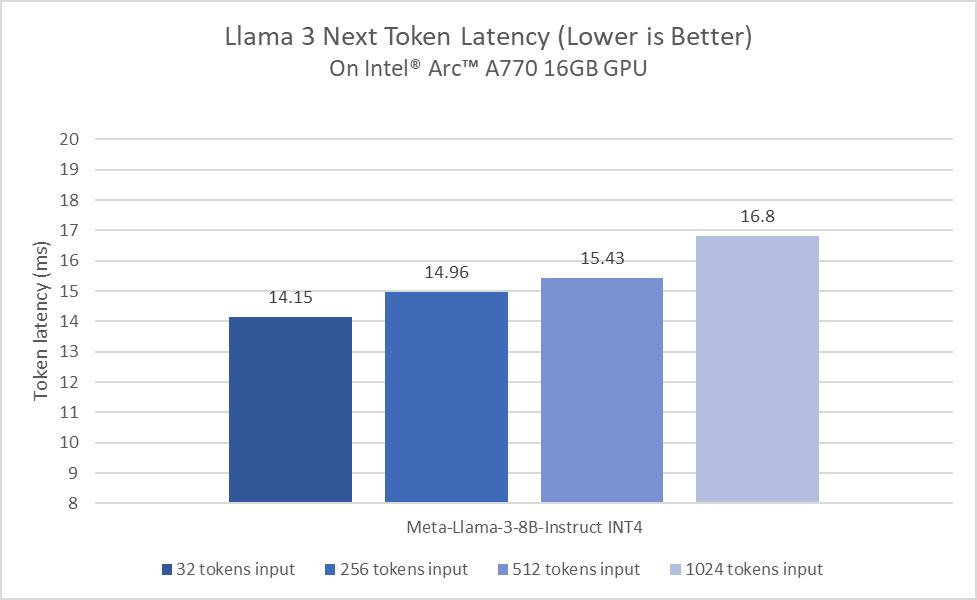
초기 평가 단계에서 Intel Core Ultra 프로세서는 이미 일반적인 사람의 읽기 속도보다 빠르게 생성됩니다. 이러한 결과는 8개의 Xe 코어, 포함된 DP4a AI 가속 및 최대 120GB/s의 시스템 메모리 대역폭을 갖춘 내장 Arc GPU에 의해 주도됩니다. 특히 차세대 프로세서로 전환함에 따라 Llama 3의 지속적인 성능 및 전력 효율성 최적화에 투자하게 되어 기쁘게 생각합니다.
Core Ultra 프로세서 및 Arc 그래픽 제품에 대한 출시일 지원을 통해 Intel과 Meta 간의 협력은 로컬 개발 수단과 수백만 개의 장치에 대한 배포를 모두 제공합니다. 인텔 클라이언트 하드웨어는 로컬 연구 및 개발에 사용되는 PyTorch 및 PyTorch용 인텔 확장, 모델 배포 및 추론을 위한 OpenVINO 툴킷을 포함한 포괄적인 소프트웨어 프레임워크 및 도구를 통해 가속화됩니다.
다음 단계: Meta는 앞으로 몇 달 안에 새로운 기능, 추가 모델 크기 및 향상된 성능을 도입할 예정입니다. 인텔은 이 새로운 LLM을 지원하기 위해 AI 제품의 성능을 계속 최적화할 것입니다.